Mô hình ngôn ngữ lớn Vistral (phiên bản tiếng Việt của Mistral) đã chính thức ra mắt với sự hợp tác của nhiều thành viên đến từ University of Oregon, LAION, Ontocord, VILM và rất nhiều cá nhân nữa.
Mời bạn tham khảo Mô hình ngôn ngữ lớn VinaLLaMA của Việt Nam có gì hot?
Mô hình ngôn ngữ lớn Vistral là gì?
Chúng tôi xin giới thiệu một mô hình ngôn ngữ lớn cho tiếng Việt mới do nhóm của Chien Van Nguyen ở University of Oregon cùng team Viet Mistral và Ontocord phát triển có tên là Vistral.
Vistral được phát triển từ mô hình Mistral 7B của tiếng Anh bằng cách mở rộng từ vựng và huấn luyện trên các dữ liệu đa dạng. Cụ thể các bước để phát triển Vistral bao gồm:
- Mở rộng từ vựng cho Mistral 7B để hỗ trợ tiếng Việt.
- Huấn luyện Mistral thêm (continual pretraining) trên dữ liệu tiếng Việt đa dạng được tinh chỉnh kỹ lưỡng.
- Huấn luyện thêm (supervised fine-tuning) trên dữ liệu instruction đa dạng với nhiều chủ đề. Trong dữ liệu này, bọn mình có thiết kế một số dữ liệu thủ công để tăng tính an toàn và khả năng cho mô hình.
- Download: https://huggingface.co/Viet-Mistral/Vitral-7B-Chat
- Demo: https://504b44c11fe7a99b98.gradio.live
- File GGUF để chạy local: https://huggingface.co/janhq/Vistral-7b-Chat-GGUF
Mô hình ngôn ngữ lớn Vistral có gì nổi bật?
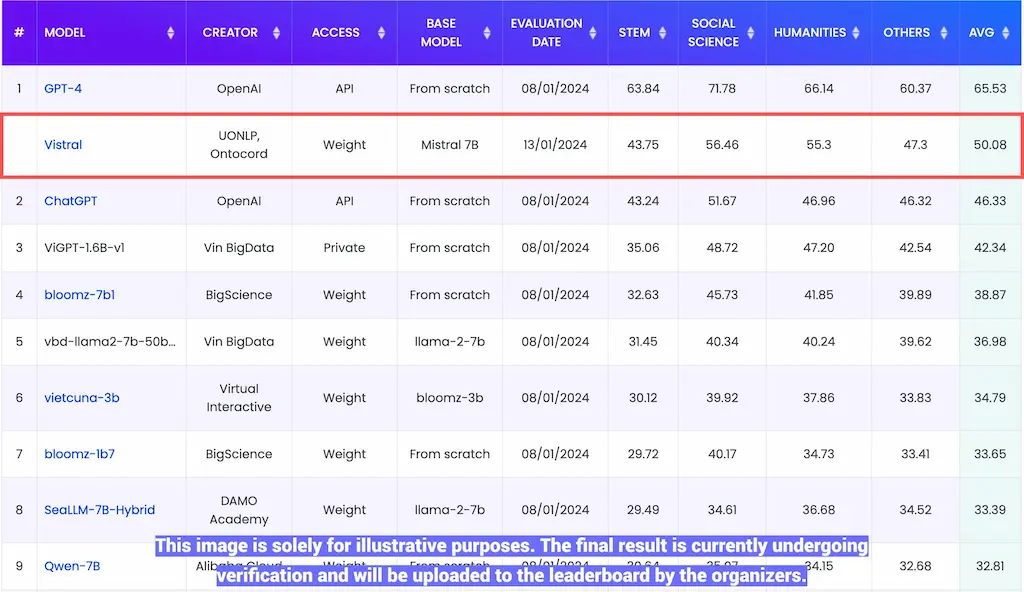
Vistral là mô hình đầu tiên của Việt Nam vượt mặt ChatGPT-3.5 trên bảng xếp hạng VMLU của Zalo.
Đánh giá của nhóm tác giả trên bộ dữ liệu leaderboard VMLU (https://vmlu. ai/leaderboard), thì Vistral đạt được 50.08% average score (average score của ChatGPT hiện tại là 46.33%). Nhóm đã gửi mô hình sang cho organizers để verify và đóng góp vào leaderboard.
Mô hình của nhóm để phục vụ mục đích nghiên cứu và tham khảo cho cộng động. Mô hình vẫn còn nhiều thiếu sót và hy vọng được cộng đồng góp ý để phát triển thêm.
Nhóm đang trong quá trình đánh giá kỹ lưỡng hơn và viết paper, nên nhóm xin chia sẻ thông tin chi tiết hơn về mô hình và cách huấn luyện sau.