Mới đây Google đã phát triển dự án Spatial VLM, một mô hình ngôn ngữ thị giác với khả năng suy luận không gian 3 chiều.
Hạn chế của các mô hình ngôn ngữ đa phương thức (MLLM)

Trước đây, các mô hình trí thông minh nhân tạo chỉ nhận biết hình ảnh và trả lời câu hỏi đơn giản. CÒn con người dễ dàng xác định các mối quan hệ không gian, chẳng hạn như vị trí của các vật thể so với nhau hoặc ước tính khoảng cách và kích thước. Sự thành thạo bẩm sinh này trong các nhiệm vụ lý luận không gian trực tiếp tương phản với những hạn chế hiện tại của VLM. Chúng ta có thể trang bị cho VLM khả năng suy luận không gian giống như con người không?
Spatial VLM là gì?
Google phát triển khung tạo dữ liệu VQA không gian 3D tự động để nâng hình ảnh 2D thành các đám mây điểm 3d theo tỷ lệ số liệu. Họ mở rộng đường dẫn dữ liệu lên tới 2 tỷ ví dụ VQA trên 10 triệu hình ảnh trong thế giới thực.
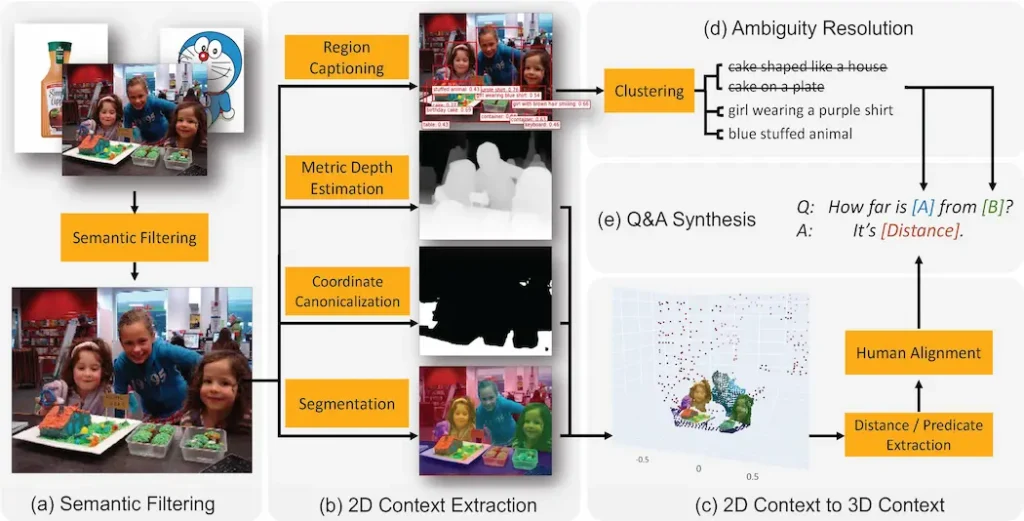
Sau đó, họ trộn dữ liệu tổng hợp vào tập huấn luyện của mô hình ngôn ngữ lớn đa phương thức để huấn luyện VLM không gian. Dữ liệu như vậy cho phép mô hình trả lời các câu hỏi suy luận không gian trực quan như những câu hỏi được liệt kê trong hình bên dưới. Những khả năng cơ bản này đóng vai trò là nền tảng cho các nhiệm vụ suy luận không gian phức tạp hơn, chẳng hạn như những nhiệm vụ đòi hỏi nhiều bước.
Với khả năng thực hiện suy luận không gian trực tiếp như con người, chúng ta có thể để SpatialVLM thực hiện suy luận không gian theo chuỗi tư duy bằng cách cho nó nói chuyện với LLM. Như chúng tôi sẽ trình bày sau trong phần thí nghiệm, khả năng suy luận trực tiếp khi kết hợp với suy luận theo chuỗi suy nghĩ có thể trả lời nhiều câu hỏi gồm nhiều bước.