Microsoft vừa ra mắt LLMLingua giúp tăng tốc độ suy luận của các mô hình ngôn ngữ lớn (LLM), đồng thời nâng cao hiệu suất và giảm kích thước mô hình xuống 20 lần.

LLMLingua là gì?
Giảm chi phí đáng kể mà hầu như không mất đi hiệu suất.
Các mô hình ngôn ngữ lớn (LLM) đã được áp dụng trong nhiều ứng dụng khác nhau do khả năng đáng kinh ngạc của chúng. Với những tiến bộ trong công nghệ như nhắc nhở chuỗi suy nghĩ (CoT) và học tập trong ngữ cảnh (ICL), các lời nhắc được cung cấp cho LLM ngày càng trở nên dài dòng, thậm chí vượt quá hàng chục nghìn mã thông báo.
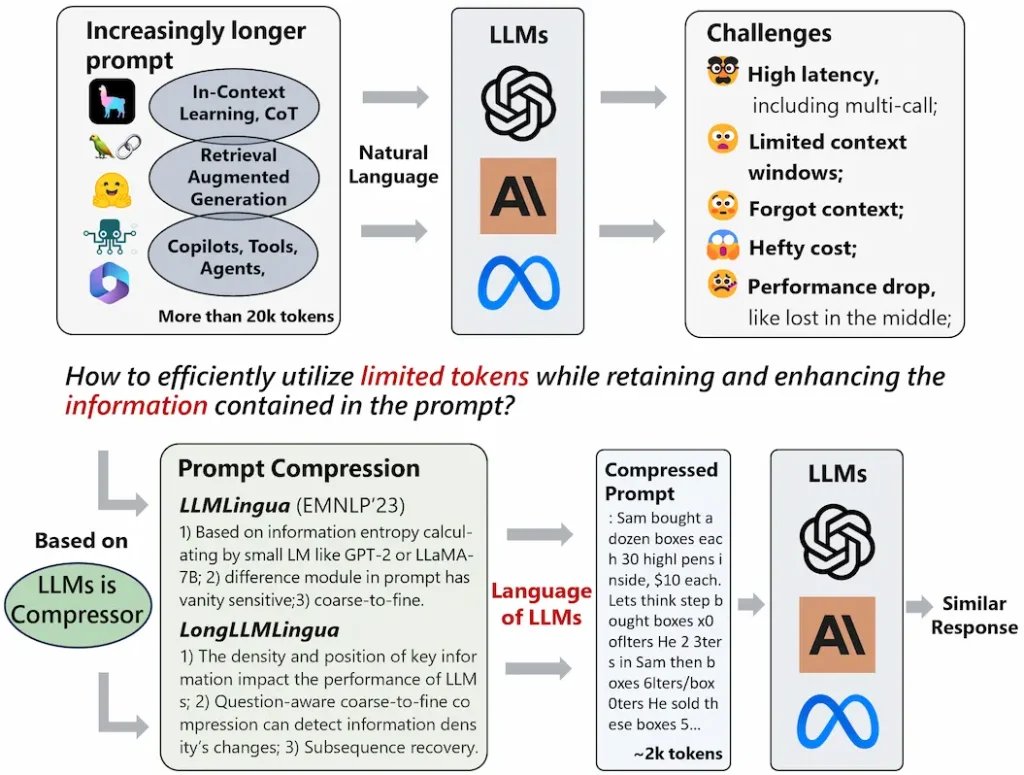
Để tăng tốc suy luận mô hình và giảm chi phí, LLMLingua là một phương pháp nén nhanh từ thô đến mịn bao gồm bộ điều khiển ngân sách để duy trì tính toàn vẹn ngữ nghĩa theo tỷ lệ nén cao, thuật toán nén lặp cấp mã thông báo để mô hình hóa tốt hơn sự phụ thuộc lẫn nhau giữa các nén được nén.
Nội dung và phương pháp dựa trên điều chỉnh hướng dẫn để căn chỉnh phân phối giữa các mô hình ngôn ngữ. Chúng tôi tiến hành thử nghiệm và phân tích trên bốn bộ dữ liệu từ các kịch bản khác nhau, ví dụ: GSM8K, BBH, ShareGPT và Arxiv-March23; cho thấy phương pháp được đề xuất mang lại hiệu suất tiên tiến và cho phép nén lên tới 20 lần mà ít bị giảm hiệu suất. Mã của chúng tôi có sẵn tại đây.
Cách sử dụng LLMLingua
Nếu sử dụng Python, có thể cài đặt LLMLingua bằng dòng lệnh:
pip install llmlinguaLLMLingua sử dụng một mô hình ngôn ngữ nhỏ gọn nhưng được huấn luyện kỹ lưỡng (ví dụ: GPT2-small, LLaMA-7B) để “lọc” lại và loại bỏ những token không cần thiết trong các câu lệnh Prompt.
Việc dùng một mô hình ngôn ngữ nhỏ gọn để lọc Prompt lại giúp câu lệnh Prompt đầu vào các LLM được “sạch” Và đúng ngữ cảnh hơn, từ đó đạt kết quả tương tự như các framework xử lý Prompt khác như LangChain hoặc LlamaIndex.